ChatGPTを安全に使うための必須ガイド
きたたく
きたたくブログ

Googlecolabにアクセスします。以下の「ノートブックを新規作成」ボタンをクリックします。

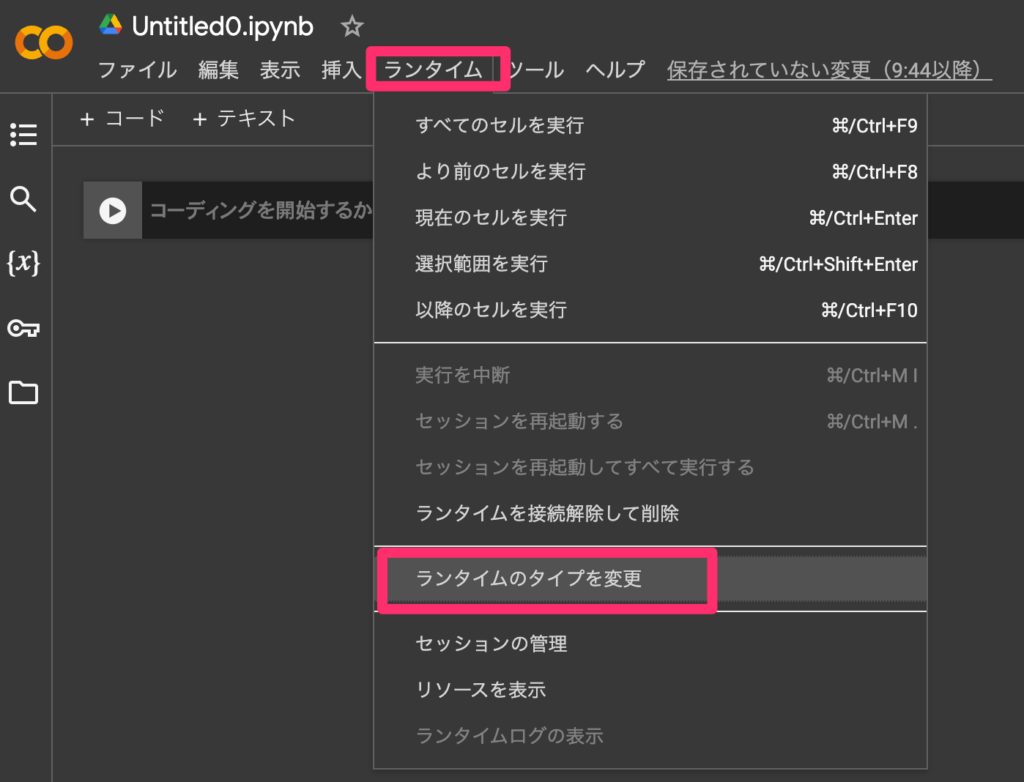
以下の画像のように、「GPU」と書いてある項目を選択します。
選択できる項目は時間によって異なる場合があります。
今回は「T4 GPU」を選びました。

GPUに変更されたことの確認を行います。
以下のコマンドを打ち、「再生ボタン」か「Shift+Enter」で実行します。
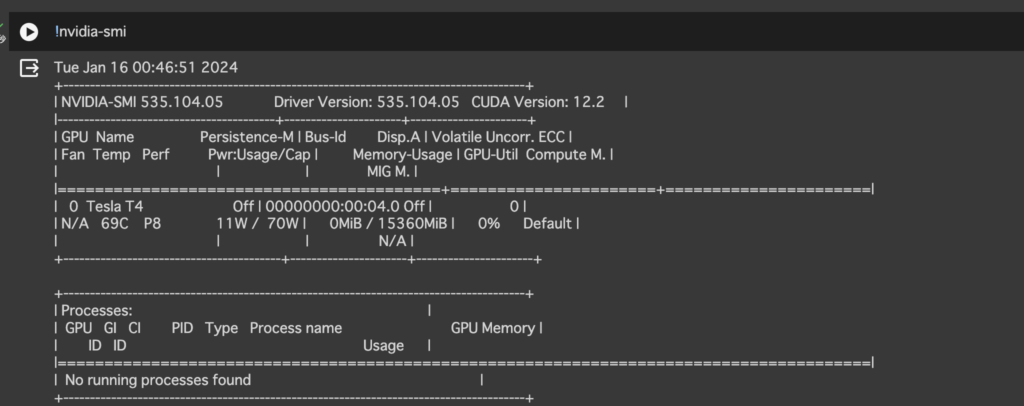
「!nvidia-smi」はGPUのモニタリングを行うコマンドです。
!nvidia-smi以下の画像のように「NVIDIA-SMI 数字」と表示されていれば大丈夫です。
「NVIDIA-SMI has failed」と表示される際は、再度GPUになっているか確認してください。
必要なライブラリのインストール
以下のコマンドでPythonのパッケージ管理ツールであるpipを使って必要なライブラリをインストールします。コマンドは「!nvidia-smi」の次の入力枠に入力します。
!pip install diffusers transformers ftfy accelerate今回は最新の以下のバージョンをインストールしました。
diffusers:0.25.0 transformers:4.35.2 ftfy:6.1.3 accelerate:0.26.1
バージョンを記事と合わせる場合は、以下のコマンドでバージョンを指定してください。
!pip install diffusers==0.25.0 transformers==4.35.2 ftfy==6.1.3 accelerate==0.26.1以下のように画面に表示されているため、transformersはすでにインストール済みでした。
Requirement already satisfied: transformers in /usr/local/lib/python3.10/dist-packages (4.35.2)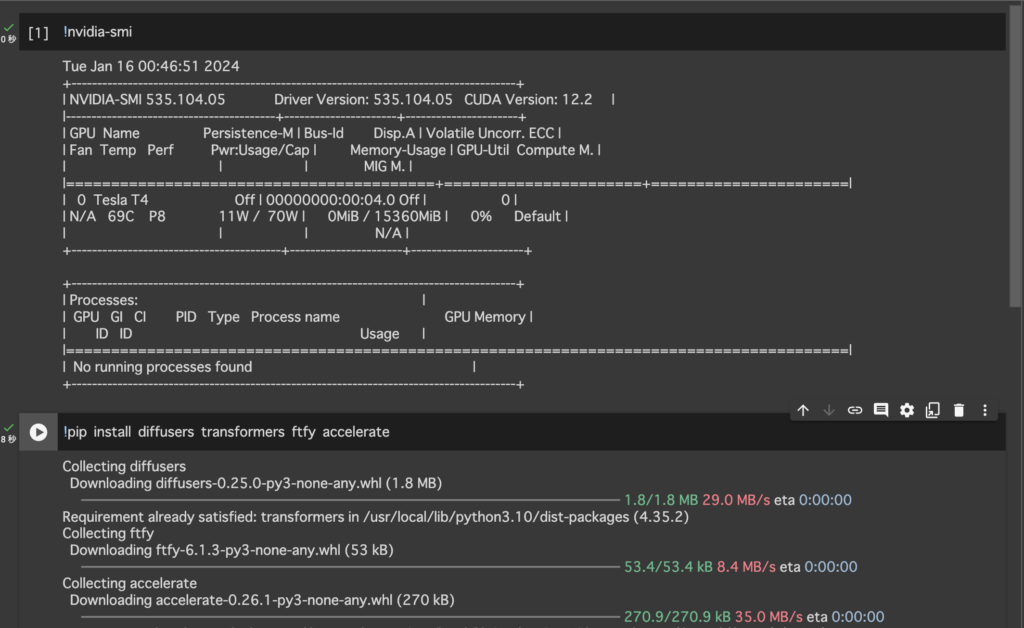

以下のコードを入力して実行します。コードはStable Diffusionを使用して、特定のテキストプロンプトに基づいて画像を生成し、その画像を保存するためのものです。
import torch
from diffusers import StableDiffusionPipeline
model_id = "CompVis/stable-diffusion-v1-4"
prompt = "best quality,dog"
device = "cuda"
seed=30
pipeline = StableDiffusionPipeline.from_pretrained(model_id).to(device)
generator = torch.Generator(device).manual_seed(seed)
with torch.autocast(device):
image = pipeline(prompt, guidance_scale=7.5, generator=generator).images[0]
image.save("test1.png")import torch
from diffusers import StableDiffusionPipelinePyTorch(torch)と、DiffusersライブラリからStableDiffusionPipelineをインポートしています。PyTorchは機械学習モデルの構築と訓練に広く使用されるフレームワークで、Diffusersは主に深層学習に基づく画像生成のためのツールを提供します。
model_id = "CompVis/stable-diffusion-v1-4"
prompt = "best quality,dog"
device = "cuda"
seed=30model_idは使用するStable Diffusionモデルのバージョンを指定します。promptは画像生成のためのテキスト指示で、ここでは品質が良い犬の画像を要求しています。deviceは計算を行うデバイスを指定しており、"cuda"はNVIDIAのGPUを使うことを意味します。seedは乱数生成器のためのシード値で、画像生成の再現性を保証するために使用されます。pipeline = StableDiffusionPipeline.from_pretrained(model_id).to(device)事前訓練済みのStable Diffusionモデルをロードし、指定されたデバイス(この場合はGPU)に移動しています。
generator = torch.Generator(device).manual_seed(seed)
with torch.autocast(device):
image = pipeline(prompt, guidance_scale=7.5, generator=generator).images[0]
image.save("test1.png")14行目 は、指定されたプロンプトに基づいて画像を生成します。guidance_scaleパラメータは、生成される画像がプロンプトにどれだけ密接に従うかを制御します(数値が大きいほど、よりプロンプトに忠実な画像が生成されます)。生成された画像はリスト形式で返されるため、最初の要素([0])を取得しています。"test1.png"という名前で保存します。
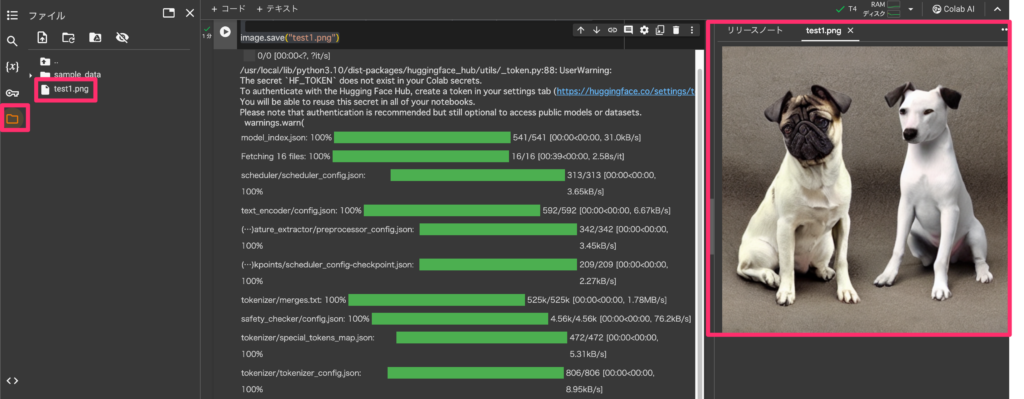
実行が終了したら、画像を確認します。画像は左側メニューのフォルダアイコンをクリックし、「test1.png」をクリックすると画面右に表示されます。
今回はプロンプトで”best quality,dog”を指定したため、犬の画像が生成されています。